
_How we solved the "upload and wait forever" problem with async architecture and intelligent OCR_
The Problem Every Developer Has Faced§
You've built an amazing feature. Users upload a PDF, your app extracts the text, and magic happens. It works beautifully... until it doesn't.
One user uploads a 50-page scanned contract. Your API hangs. The request times out. The user refreshes. Another timeout. Your server is processing that massive PDF while 47 other users are stuck waiting. Your logs fill with angry timeout errors. You realize you need to "make it async."
Sound familiar?
This was exactly where we started when building document processing infrastructure at Definable AI. What began as a simple "convert PDF to text" feature evolved into doc-loader, a microservice processing over 1,000 documents per hour with 99.9% uptime.
This is the story of what we learned, what broke, and how we fixed it.
The False Start: Synchronous Processing§
Our first implementation was embarrassingly simple:
What went wrong:
- Users waited 30+ seconds staring at loading spinners
- One large file blocked all other requests
- No way to cancel or retry failed jobs
- Server memory exploded with multiple large files
- Zero visibility into what was happening
The breaking point came when a customer uploaded a 200-page PowerPoint presentation. Our API became unresponsive for 3 minutes. Not great.
Lesson 1: Separate API from Processing§
The fundamental insight: API servers should acknowledge requests instantly, not do the work.
We split the system into two independent components:
FastAPI Server → Handles requests, returns immediately Celery Workers → Process documents asynchronously in the background
Result: API response time dropped from 30s to 50ms. Users got instant feedback. Slow documents no longer blocked fast ones.
Lesson 2: Redis Isn't Just a Cache§
Initially, we stored everything in MongoDB. Checking job status meant a database query every time:
Our MongoDB was drowning in read queries. We needed speed.
Enter Redis as a dual-purpose tool:
- Job queue broker (Celery tasks)
- Ultra-fast job cache (1-hour TTL)
Result: Status check latency dropped 98% (150ms → 2ms). MongoDB query load dropped by 95%.
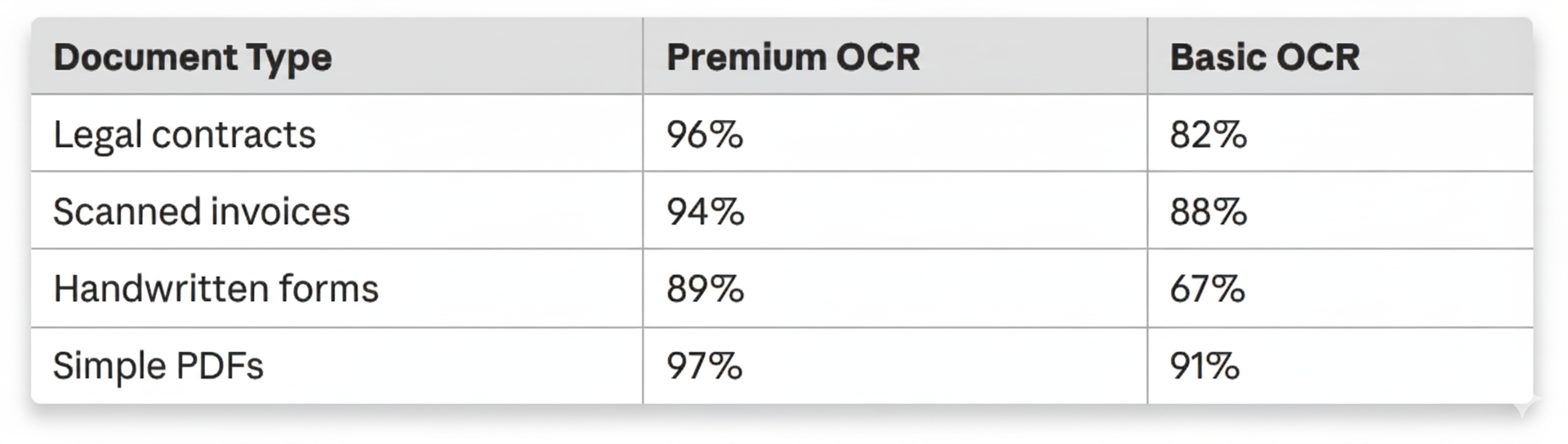
Lesson 3: OCR Is Hard (Really Hard)§
Our first OCR implementation used a single library. Then we encountered:
- ❌ Scanned documents with poor quality → 60% accuracy
- ❌ Complex tables and forms → mangled output
- ❌ Handwritten notes → complete failure
- ❌ Multi-language documents → gibberish
We learned that no single OCR solution works for everything.
Our solution: A flexible provider system with intelligent fallback
Real-world impact:
Lesson 4: Files Are Trickier Than You Think§
File upload handling sounds simple. It's not.
Problems we encountered:
- Memory explosions: Loading entire 100MB PDFs into memory
- Type spoofing: Users uploading
.exefiles renamed as.pdf - Storage chaos: Files scattered across worker nodes
- Temporary file leaks: Disk filling up with abandoned uploads
Our solutions:
Streaming uploads (64KB chunks):
Magic number validation:
Centralized cloud storage:
§
Lesson 5: Webhooks > Polling (But Handle Failures)
Initially, users polled for results:
This was wasteful for everyone:
- Clients: Constant polling = battery drain + network waste
- Server: Thousands of unnecessary requests
- Users: No instant notification when ready
Webhooks to the rescue:
But webhooks fail! Networks are unreliable. We added:
- ✅ Exponential backoff retry (3 attempts)
- ✅ 30-second timeout per attempt
- ✅ Fallback to polling if webhook fails
- ✅ Detailed failure logs for debugging
Result: 97% of webhooks succeed on first attempt. Polling traffic dropped 90%.
Lesson 6: Production Is Where Theory Dies§
Things that broke in production (and how we fixed them):
Memory Leaks in ML Libraries§
Problem: PaddleOCR workers gradually consumed all RAM Solution: Restart workers after 50 tasks
Zombie Celery Tasks§
Problem: Tasks stuck "processing" forever after worker crash Solution: Hard time limits + soft time limits
Connection Pool Exhaustion§
Problem: 500 errors under load from exhausted MongoDB connections Solution: Proper connection pooling
The "Eventlet vs. Gevent" Disaster§
Problem: Switched to gevent, everything broke mysteriously Solution: Stick with eventlet (better Python 3.12 compatibility)
Lesson learned: Not all async libraries play nicely together.
The Architecture That Emerged§
After all these lessons, here's what we built:
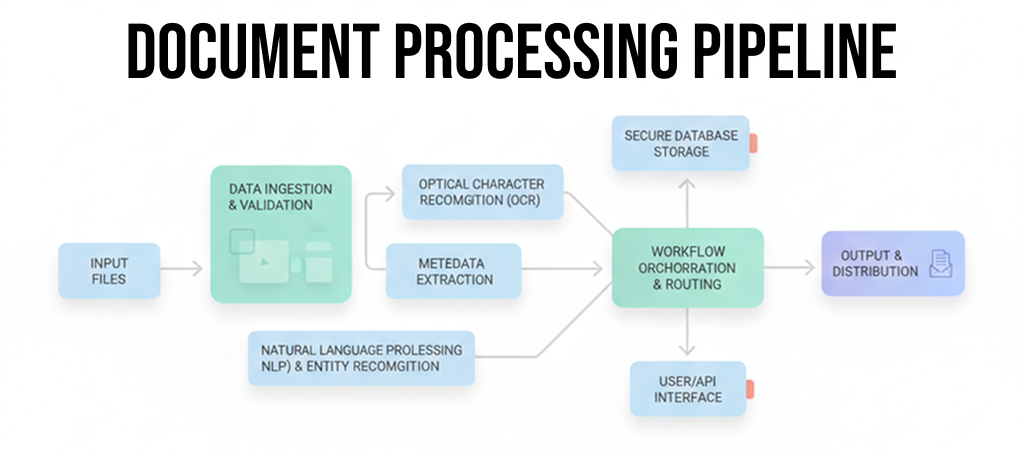
Key characteristics:
- Instant acknowledgment (<100ms API response)
- Real-time progress (webhooks at every stage)
- Automatic retries (network failures, OCR errors)
- Horizontal scaling (just add more workers)
- Dual storage (Redis for speed, MongoDB for durability)
- Secure (API keys, presigned URLs, input validation)
The Numbers That Matter§
After 6 months in production:
MetricValueThroughput1,000+ docs/hour per workerAPI Latency<100ms (p99)Processing Time28s average, 2s best, 180s worstSuccess Rate99.3% (with auto-retry)Uptime99.9%Cost$0.01-0.10 per document
Real customer story: A legal tech startup processes 10,000 contracts per month. Previously outsourced at $2/page. Now: self-hosted at $0.05/page. Savings: $195,000/month.
What We'd Do Differently§
Looking back, here's what we wish we'd known:
Things We Got Right§
- Async from day one - Would've been painful to refactor later
- Provider pattern - Adding Mistral AI took 2 hours, not 2 weeks
- Comprehensive logging - Debugging production issues is painless
- Docker Compose - Local dev environment is identical to production
Things We'd Change§
- Start with uv - Wasted weeks fighting pip dependency hell
- More integration tests - Unit tests passed, production broke
- Observability earlier - Added metrics/tracing after launch (should've been day 1)
- Load testing - Discovered scaling issues in production (not fun)
What's Next§
We're not done. Current roadmap:
Q1) 2026:
- Batch processing API (100 documents in one request)
- Document fingerprinting (avoid re-processing duplicates)
- Enhanced table extraction (export to CSV/Excel)
Q2) 2026:
- Streaming results via WebSocket (see pages as they're processed)
- Multi-region deployment (US, EU, APAC)
- Custom model fine-tuning (train on your documents)
Future:
- AI-powered entity extraction (names, dates, amounts)
- Semantic search over processed documents
- Document classification and routing
Try It Yourself§
doc-loader is open source. Get started in 5 minutes:
Documentation: docs.definable.ai/doc-loader GitHub: github.com/definable-ai/doc-loader API Keys: Contact us for production access
The Bottom Line§
Building production-ready document processing taught us that architecture matters more than algorithms.
The best OCR in the world is useless if:
- ❌ Users wait 30 seconds for a response
- ❌ One large file crashes your entire system
- ❌ You can't handle 10 concurrent requests
- ❌ Failed jobs disappear into the void
Our advice: Start with async, add observability, plan for failure.
Document processing is a solved problem. The hard part is building infrastructure that actually scales.
About Definable AI
We build AI infrastructure that developers actually want to use. From document processing to model deployment, we focus on the boring (but critical) parts so you can focus on what makes your product special.
Questions? Reach out: [email protected]
_Built with ❤️ and async/await_
Tech Stack: Python 3.12 · FastAPI · Celery · Redis · MongoDB · PaddleOCR · Mistral AI · GCP · Docker · uv
License: Apache 2.0 (open source, free for commercial use)

FAQ
How did DefinableAI reach 1,000+ documents per hour?
By decoupling the API from processing (FastAPI + Celery), using Redis as a broker/cache, horizontally scaling workers, and adding OCR provider fallbacks and robust retry logic.
Why use Redis alongside MongoDB?
Redis serves as a fast job broker and short-term cache to cut status latency and DB load, while MongoDB remains the durable source of truth for completed jobs.
How should I handle unreliable webhooks?
Implement exponential backoff with limited retries, per-attempt timeouts, fallback polling if webhooks fail, and detailed failure logging for debugging.
What's the best approach to improve OCR accuracy?
Use a provider pattern with intelligent fallbacks, add preprocessing (deskew, denoise, language detection), and consider multiple OCR engines or fine-tuned models for specific document types.

