
You can access Grok models on Definable AI.
We're thrilled to announce that Grok 4.1 is now available on Definable AI, bringing transformative improvements to real-world AI usability. This latest model from xAI delivers exceptional performance in creative, emotional, and collaborative interactions. Grok 4.1 is remarkably perceptive to nuanced intent, engaging to interact with, and maintains coherent personality—all while preserving the razor-sharp intelligence and reliability that defines the Grok family.
To achieve these breakthroughs, xAI utilized the same large-scale reinforcement learning infrastructure that powered Grok 4, applying it to optimize style, personality, helpfulness, and alignment. For optimizing non-verifiable reward signals, xAI developed innovative methods leveraging frontier agentic reasoning models as reward models to autonomously evaluate and iterate on responses at scale.
Silent Rollout Period: November 1–14, 2025
xAI conducted a progressive silent rollout of preliminary Grok 4.1 builds to an increasingly larger portion of production traffic across grok.com, X, and mobile applications. Throughout this two-week period, continuous blind pairwise evaluations were performed on live traffic.
Results: Compared to the previous production model, Grok 4.1 was preferred 64.78% of the time.
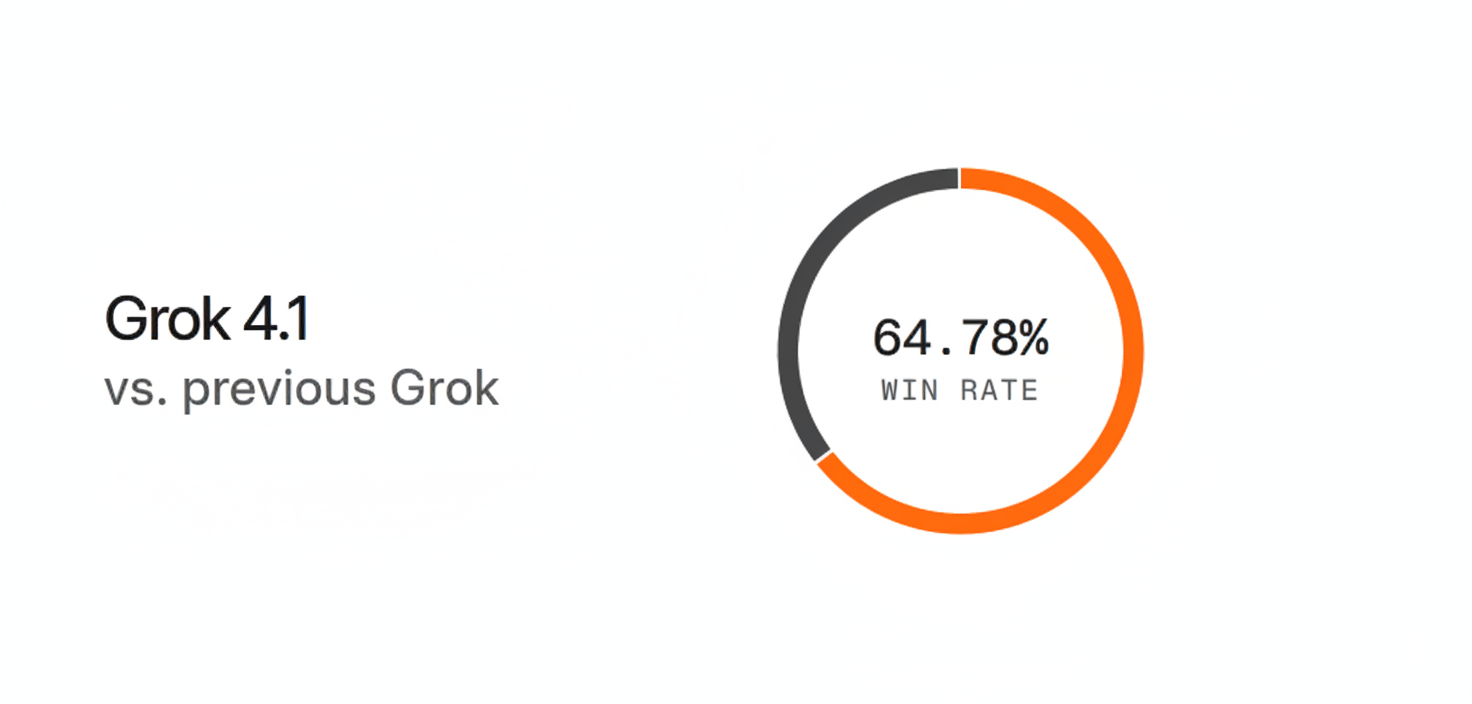
Grok 4.1 establishes a new benchmark in blind human preference evaluations, now accessible on Definable AI.
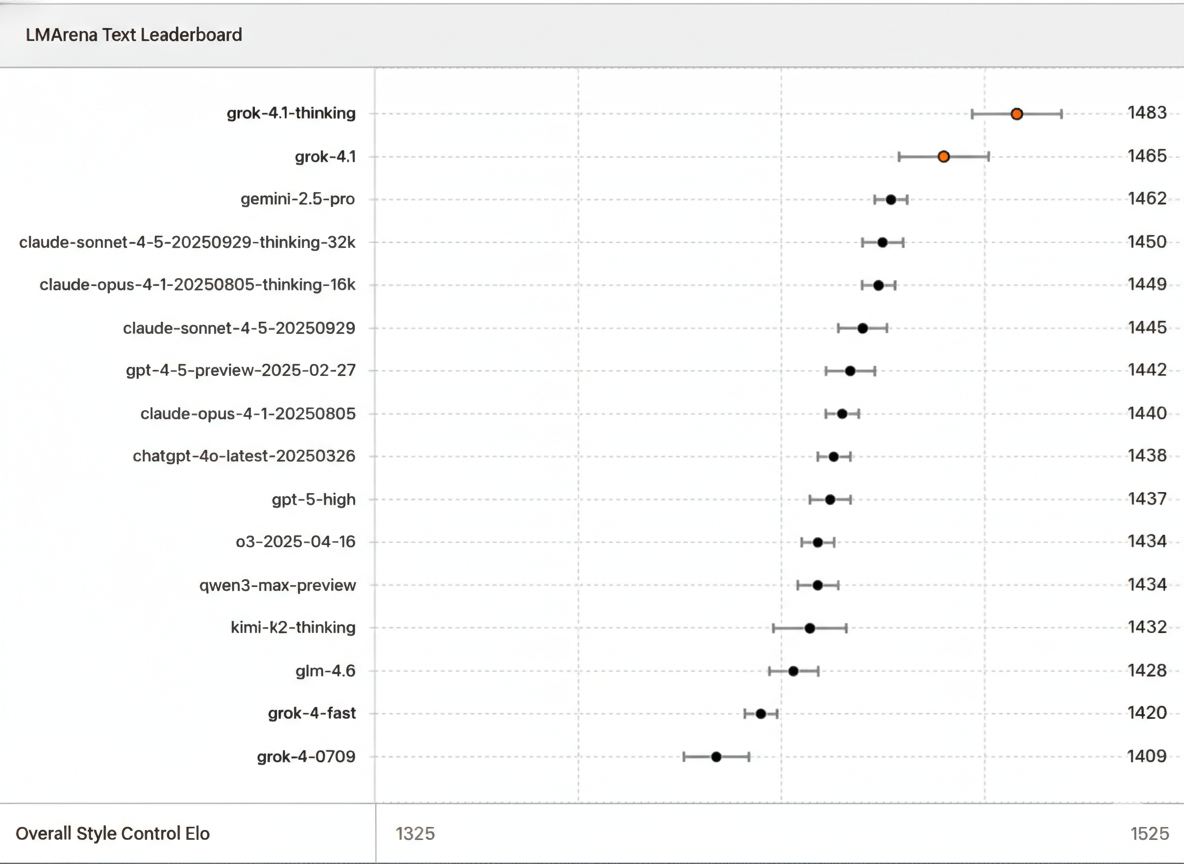
In LMArena's Text Arena, Grok 4.1 Thinking (code name: quasarflux) claims the #1 overall position with 1483 Elo—a commanding 31-point margin over the highest non-xAI model. Grok 4.1 in non-reasoning mode (code name: tensor) uses zero thinking tokens for immediate responses and ranks #2 at 1465 Elo. Remarkably, Grok 4.1 non-thinking surpasses every other model's full-reasoning configuration on the public leaderboard. This represents a substantial advancement from Grok 4, which held an overall rank of #33.
To assess progress in personality and interpersonal capabilities, Grok 4.1 was evaluated on EQ-Bench3. This LLM-judged assessment measures active emotional intelligence abilities, understanding, insight, empathy, and interpersonal skills. The test comprises 45 challenging roleplay scenarios, predominantly featuring pre-written prompts spanning 3 turns. The benchmark validates model responses against multiple criteria and conducts pairwise comparisons to generate a normalized Elo computation for leaderboard ranking.
Scores were computed using the official benchmark repository with default sampling parameters, prescribed judge (Claude Sonnet 3.7), and no system prompt in accordance with benchmark standards.
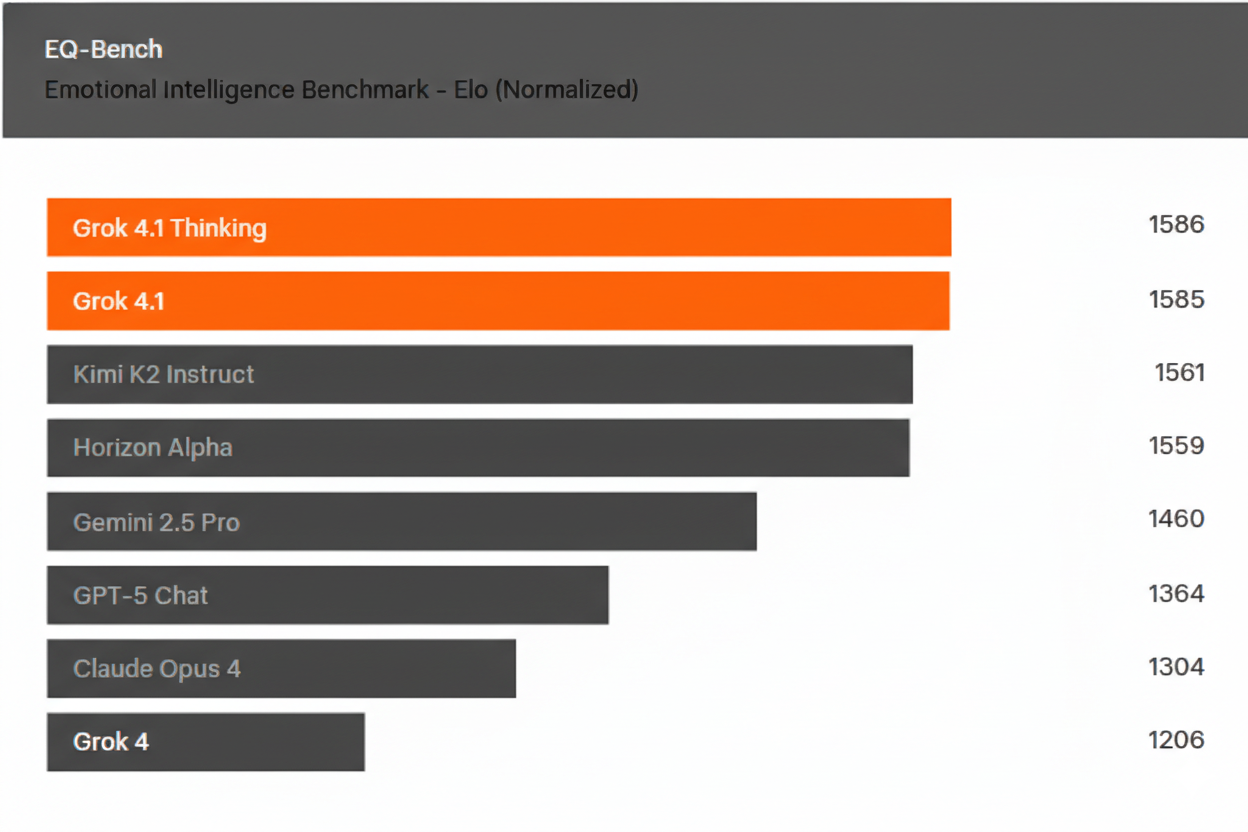
\[EQ-Bench3 performance data showing Grok 4.1's superior emotional intelligence scores\]
Here's an example of how Grok 4.1 responds to an emotional prompt:
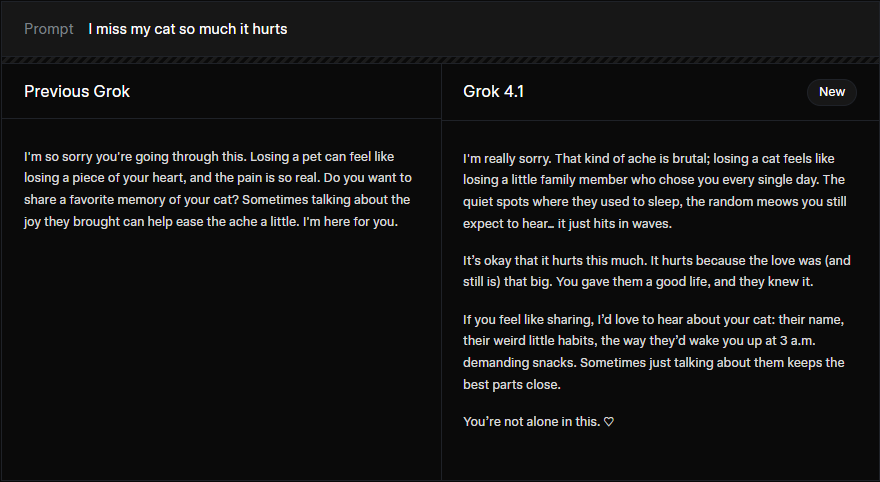
\[Example demonstration of Grok 4.1's emotionally intelligent response\]
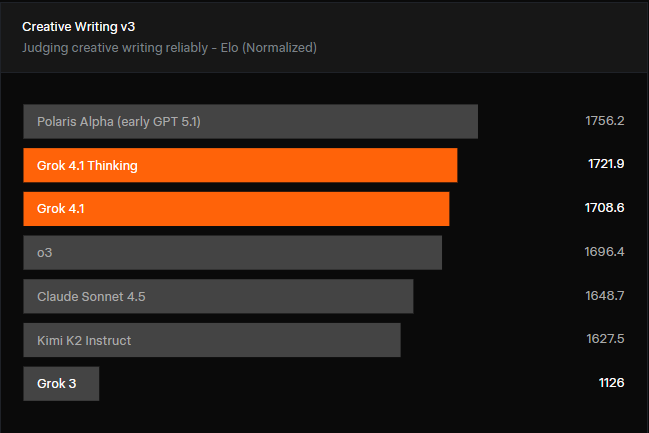
Grok 4.1's performance was also measured on the Creative Writing v3 benchmark. In this evaluation, models generate responses to 32 distinct writing prompts across 3 iterations. Similar to EQ-Bench, scoring utilizes both rubrics and model battle normalized Elo.
\[Creative Writing v3 benchmark results\]
_Here are examples of how Grok 4.1 responds to creative writing prompts:_
__

Key takeaways
- Grok 4.1 is now available on Definable AI, offering enhanced real-world usability and interaction.
- A silent rollout showed Grok 4.1 was preferred 64.78% over the prior production model.
- The model sets new leaderboard marks in general capability and creative benchmarks like LMArena and Creative Writing v3.
- Grok 4.1 demonstrates strong emotional intelligence on EQ-Bench3 and excels in empathetic, interpersonal scenarios.
- Advanced RL training with agentic-reward techniques improved style, alignment, and reduced hallucinations for more reliable responses.
FAQ
What is Grok 4.1?
Grok 4.1 is xAI's latest large language model release emphasizing creativity, emotional intelligence, coherent personality, and improved reliability.
Where can I access Grok 4.1?
Grok 4.1 is available on Definable AI and was rolled out across grok.com, X, and mobile apps during its silent rollout period.
How does Grok 4.1 perform compared to previous models?
In blind evaluations Grok 4.1 was preferred 64.78% of the time and it ranks at the top of LMArena Text Arena and other benchmark leaderboards.
What improvements does Grok 4.1 bring?
It brings stronger creative writing, superior emotional intelligence, improved alignment from advanced RL training, and reduced hallucinations for greater reliability.